Visual Studio C++ Native Unit Test 짱

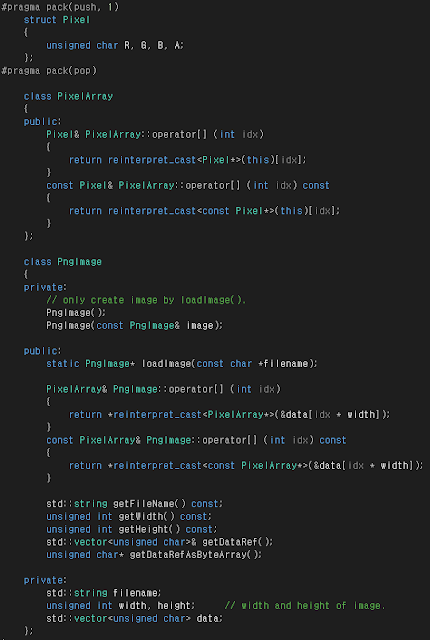
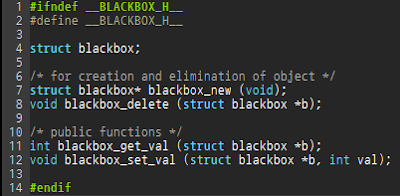
Visual Studio C++에서 Native Unit Test를 이용해보았다. 짱 좋다! method혹은 class 별로 Unit Test를 하는 습관을 길러야 겠다~ 기억할 것) 1. 테스트 프로젝트 (테스트할 프로젝트)가 export하는 class, function등에 대해서만 테스트 가능한 것 같다. (테스트 프로젝트의 구성형식을 .lib로 바꾸면 된다! 근데 안바꾸고도 할 수 있는 방법 없으려나?? ㅠㅠ .obj 을 다 인클루드하는 것 불편하고,,,another project와 함께 unite되서 build되는 그런 거 없나??? ㅠㅠ) 사진들------------------------- Unit Test 코드이다. testcase를 생성해서 test를 진행하면 된다. Assert::??? 를 이용해서 test성공여부를 결정할 수도 있다. 테스트를 하면 이렇게 테스트 성공 여부와 경과 시간이 뜬다. 테스트 출력 결과도 볼 수 있다~